
Agent S: Ein offenes Agentic Framework, das Computer wie ein Mensch nutzt
Hallo! Vor ein paar Monaten hielt ich an der Princeton University einen Vortrag über meine Gedanken zu Agenten und Simular. Ich dachte mir, ich sollte eine Zusammenfassung zusammenstellen und daraus einen Blogbeitrag machen.
Modernste Leistung
Mein erster Job war als wissenschaftlicher Mitarbeiter bei Google DeepMind, wo ein wichtiger Teil meiner Rolle darin bestand, mit verschiedenen Google-Produktteams zusammenzuarbeiten, um Möglichkeiten für die Anwendung unserer hochmodernen KI-Technologie zu identifizieren. Ein Googler stellte mir jedoch eine völlig andere Frage, die letztendlich zu meiner Entscheidung geführt haben könnte, DeepMind zu verlassen und Simular zu gründen.
Agent S ist ein neuer Agent
Rahmen entworfen, um zu ermöglichen
Computer zur Verwendung als
intuitiv, wie es ein Mensch tun würde
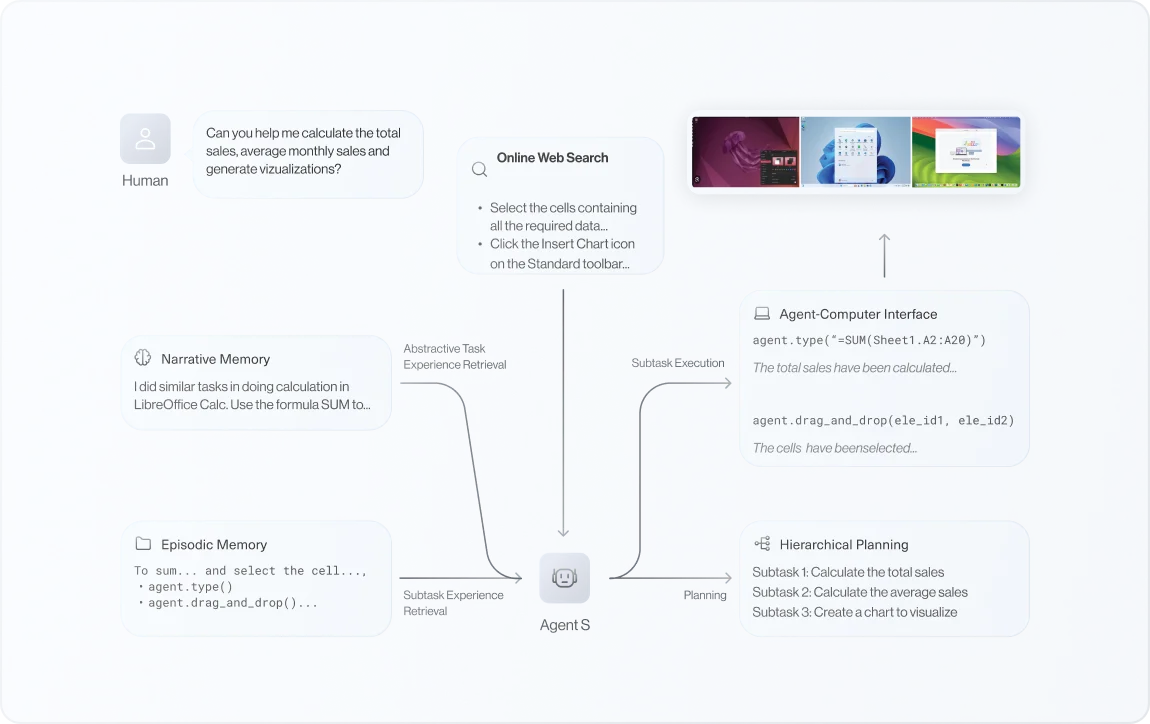
Wir führen eine erfahrungsgestützte hierarchische Planungsmethode ein. Diese Methode nutzt Online-Webwissen für aktuelle Informationen über sich häufig ändernde Software und Websites sowie Narrative Memory, um Erfahrungen auf hoher Ebene aus vergangenen Interaktionen zu nutzen. Agent S unterteilt komplexe Aufgaben in überschaubare Unteraufgaben und nutzt Episodic Memory zur schrittweisen Anleitung. So verfeinert er kontinuierlich seine Aktionen und lernt aus Erfahrungen, um eine anpassungsfähige und effektive Aufgabenplanung zu erreichen.
Zusammenfassung
Wir präsentieren Agent S, ein offenes agentisches Framework, das ermöglicht autonome Interaktion mit Computern über eine grafische Benutzeroberfläche (GUI), die darauf abzielt, die Interaktion zwischen Mensch und Computer durch die Automatisierung komplexer, mehrstufiger Aufgaben zu transformieren
Zu diesem Zweck führt Agent S eine erfahrungsgestützte hierarchische Planung ein, die aus der externen Wissenssuche und dem Abrufen interner Erfahrungen auf mehreren Ebenen lernt und so eine effiziente Aufgabenplanung und Ausführung von Unteraufgaben ermöglicht.
Darüber hinaus verwendet es eine Agent-Computer-Schnittstelle, um die Denk- und Kontrollfähigkeiten von GUI-Agenten auf der Grundlage multimodaler Large Language Models besser zu ermitteln. Die Auswertung anhand des OSWorld-Benchmarks zeigt, dass Agent S den Ausgangswert in Bezug auf die Erfolgsquote um 9,37% übertrifft (eine relative Verbesserung von 83,6%) und entspricht einem neuen Stand der Technik. Eine umfassende Analyse unterstreicht die Wirksamkeit einzelner Komponenten und liefert Erkenntnisse für zukünftige Verbesserungen.
Darüber hinaus zeigt Agent S eine breite Generalisierbarkeit auf verschiedene Betriebssysteme auf einem neu veröffentlichten
Windows AgentArena-Benchmark.
Agent S befasst sich mit drei zentralen Herausforderungen bei der Automatisierung von Computeraufgaben:

Aufgabenanweisung
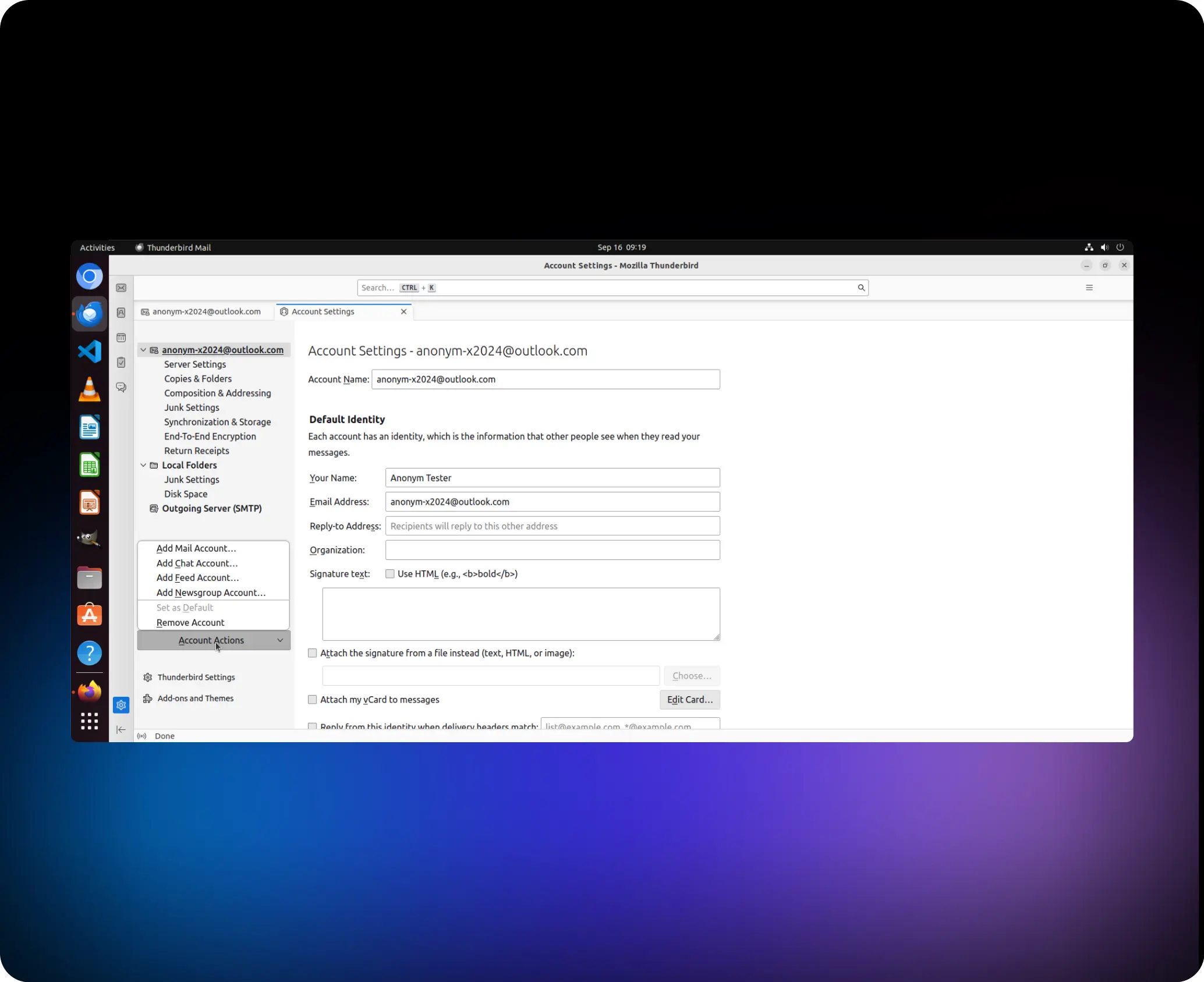
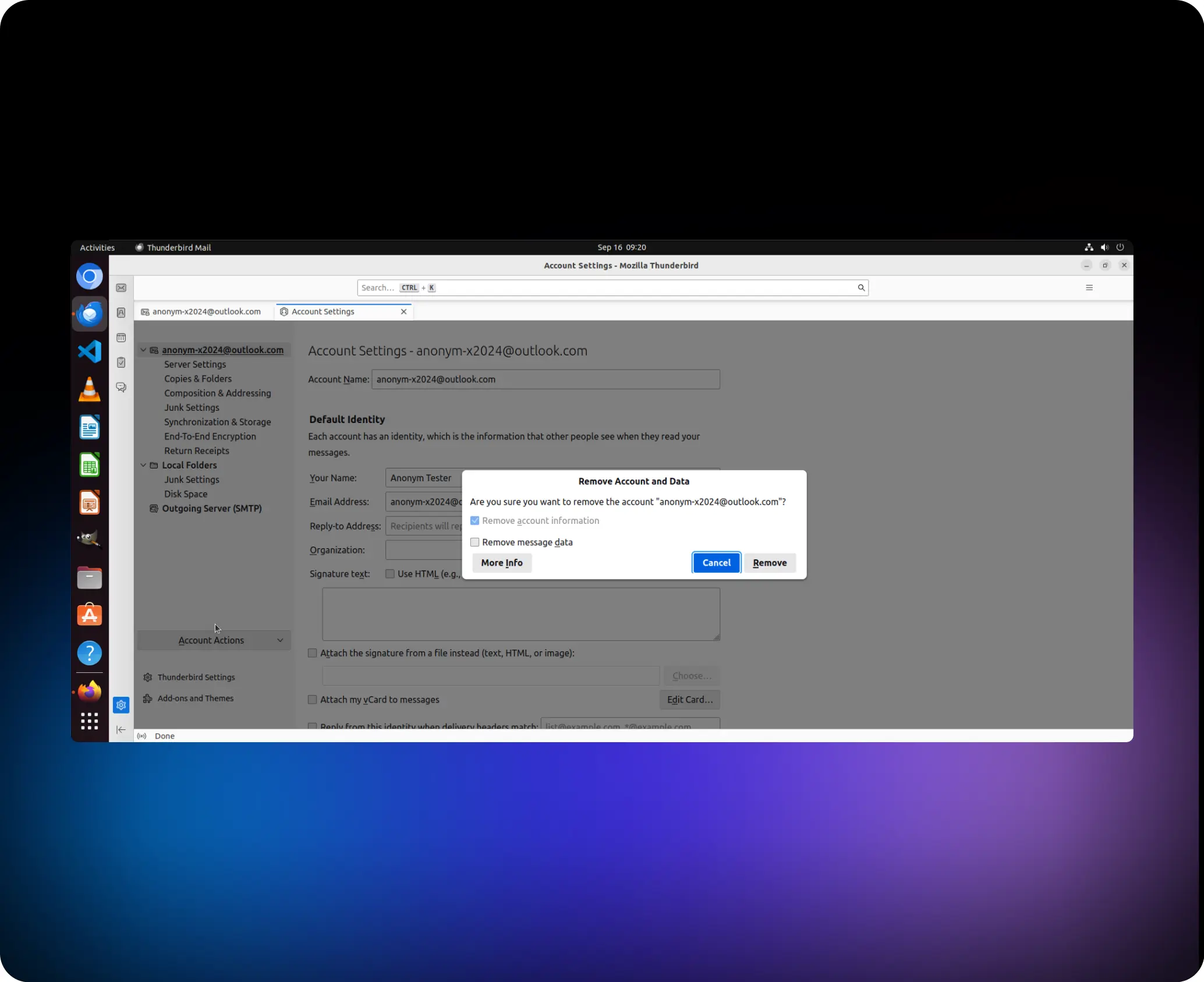
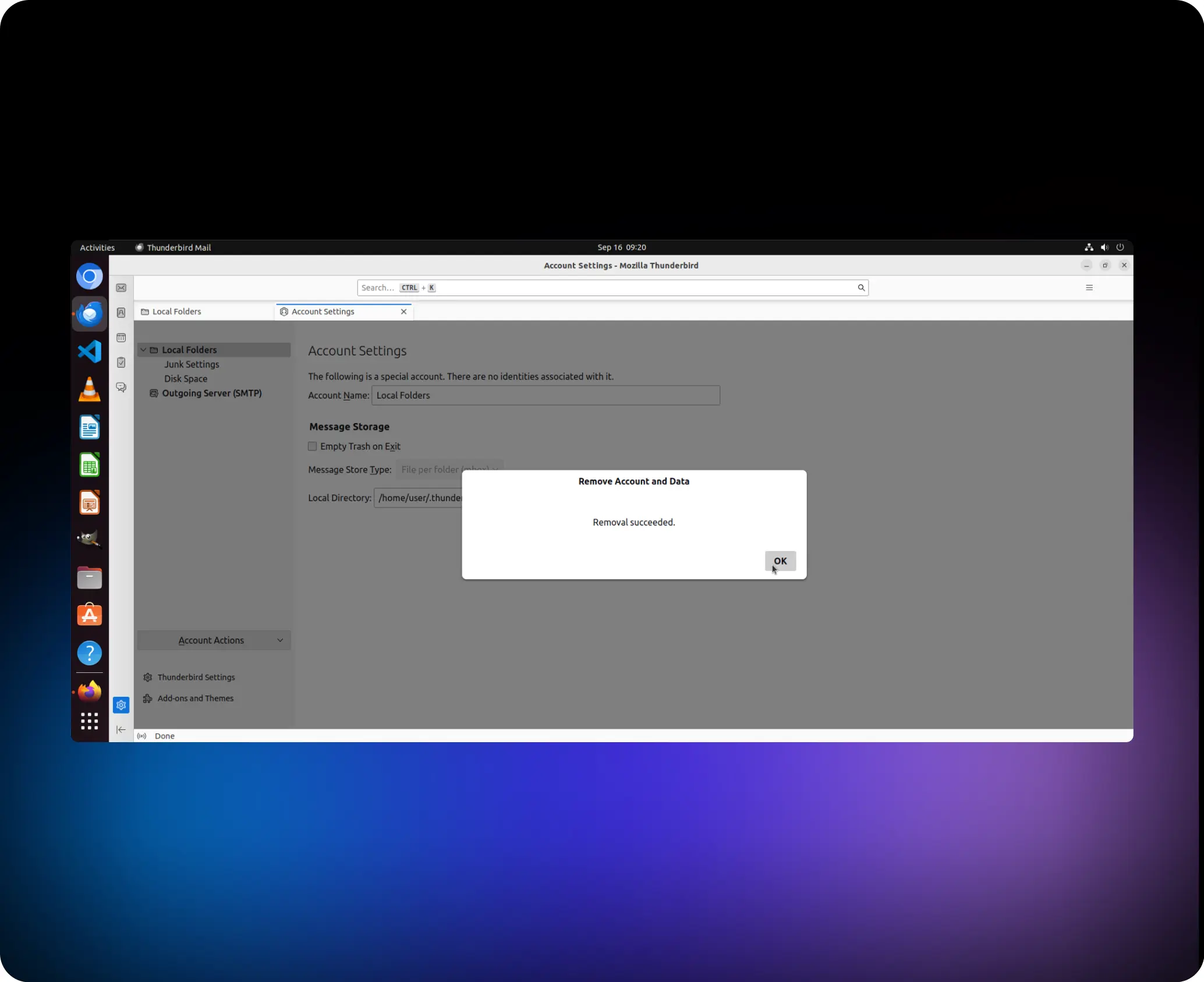
Hilf mir dabei entferne das Konto „anonym-x2024@outlook.com“
01
agent.click (41,1, „links“)

02
agent.switch_applications („Thunderbird“)
03
agent.click (95,1, „links“)
04
agent.click (86, 1, „links“)
05
agent.click (93, 1, „links“)
06
agent.click (149, 1, „links“)
.webp)
.webp)
Überblick von Agent S Framework
Ausgehend von der Aufgabe Tu und der anfänglichen Umgebungsbeobachtung 0o führt der Manager eine erfahrungsgestützte hierarchische Planung durch, bei der Webwissen und narratives Gedächtnis verwendet werden, um die Unteraufgaben So,..., Sn zu erstellen. Für jedes Si nutzt Worker Wi das episodische Gedächtnis, um zum Zeitpunkt t eine Aktion zu generieren, die vom ACI ausgeführt wird, um die nächste unmittelbare Beobachtung ot+1 zurückzugeben. Ein Selbstbewertungsmodul schließt den Kreislauf, indem es die zusammengefassten Trajektorien der Teilaufgabe und der gesamten Aufgabe im narrativen und episodischen Gedächtnis speichert.
Pipeline von Aufbau des Speichers und Update
Die Pipeline zur Speicherkonstruktion und -aktualisierung, die zwei Phasen umfasst: Selbstüberwachte Erkundung und kontinuierliche Speicheraktualisierung. Das anfängliche narrative und episodische Gedächtnis wird durch einige zufällig kuratierte Aufgaben während der Explorationsphase konstruiert und dann auf der Grundlage der Inferenzaufgaben kontinuierlich aktualisiert.
Hauptergebnis
Diese Tabelle zeigt den Leistungsvergleich zwischen Agent S und den Basismodellen, der für das gesamte OSWorld-Testset ausgewertet wurde. Für das GPT-4o-Modell erreicht Agent S eine Gesamterfolgsrate von 20,58% und verdoppelt damit fast die Leistung des besten entsprechenden Ausgangswerts (GPT-4o mit 11,21%).
Agent S übertrifft die Ausgangswerte bei den Aufgaben „Täglich“ und „Professionell“ durchweg und erreicht dort eine Erfolgsquote von 27,06% bzw. 36,73%, verglichen mit den besten Ausgangsergebnissen von 12,33% bzw. 14,29%. Diese Aufgaben werden häufig im täglichen Leben verwendet oder sind mit wissensintensiven professionellen Anwendungen verbunden, die mehr von der Retrieval-Erweiterung von Agent S profitieren. Sowohl Claude-3.5-Sonnet als auch GPT-4o übertreffen die Basisversionen bei den meisten Aufgaben. Claude-3.5-Sonnet schneidet bei den Aufgaben „Daily“ und „Professional“ sogar besser ab als GPT-4o.
Die Ergebnisse belegen die verbesserte Fähigkeit von Agent S, vielfältige und komplexe Aufgaben effektiver zu bewältigen als die Basisansätze.
Analyse
Um die Wirksamkeit der einzelnen Module von Agent S zu demonstrieren, haben wir eine Untergruppe von 65 stratifiziert.
Instanzen, Testsubstanz aus dem vollständigen Testsatz für die Ablationsstudie. In Anbetracht der Inferenzkosten verwendeten wir GPT-4o als
LLM-Backbone für alle Ablationsstudien sowohl für den Ausgangswert als auch für Agent S.
Aus Erfahrung zu lernen verbessert das Domänenwissen von GUI-Agenten
Wichtigste Ergebnisse der Erfolgsquote (%) für den vollständigen OSWorld-Testsatz aller 369 Testbeispiele
Durch das Lernen aus universellen Erfahrungen, die als Web-Wissen verfügbar sind, kann Agent S fundierte Pläne für eine Vielzahl von Aufgaben erstellen, was die größte Wirkung hat. Das Lernen aus narrativen und episodischen Erinnerungen ergibt eine effektive Synergie mit dem Web-Retrieval. Die Ergebnisse zeigen detailliert, wie sich deren Ablation auf die Fähigkeit des Agenten auswirkt, komplexe Aufgaben zu bewältigen, was den Wert des Erfahrungslernens unterstreicht. Diese Ergebnisse zeigen, dass jede Komponente eine entscheidende Rolle bei der Erweiterung des Domänenwissens des Agenten spielt. Wenn alle drei Komponenten (ohne Alle) entfernt werden, verschlechtert sich die Leistung erheblich, was zeigt, wie wichtig es ist, bei der Planung aus Erfahrungen zu lernen.
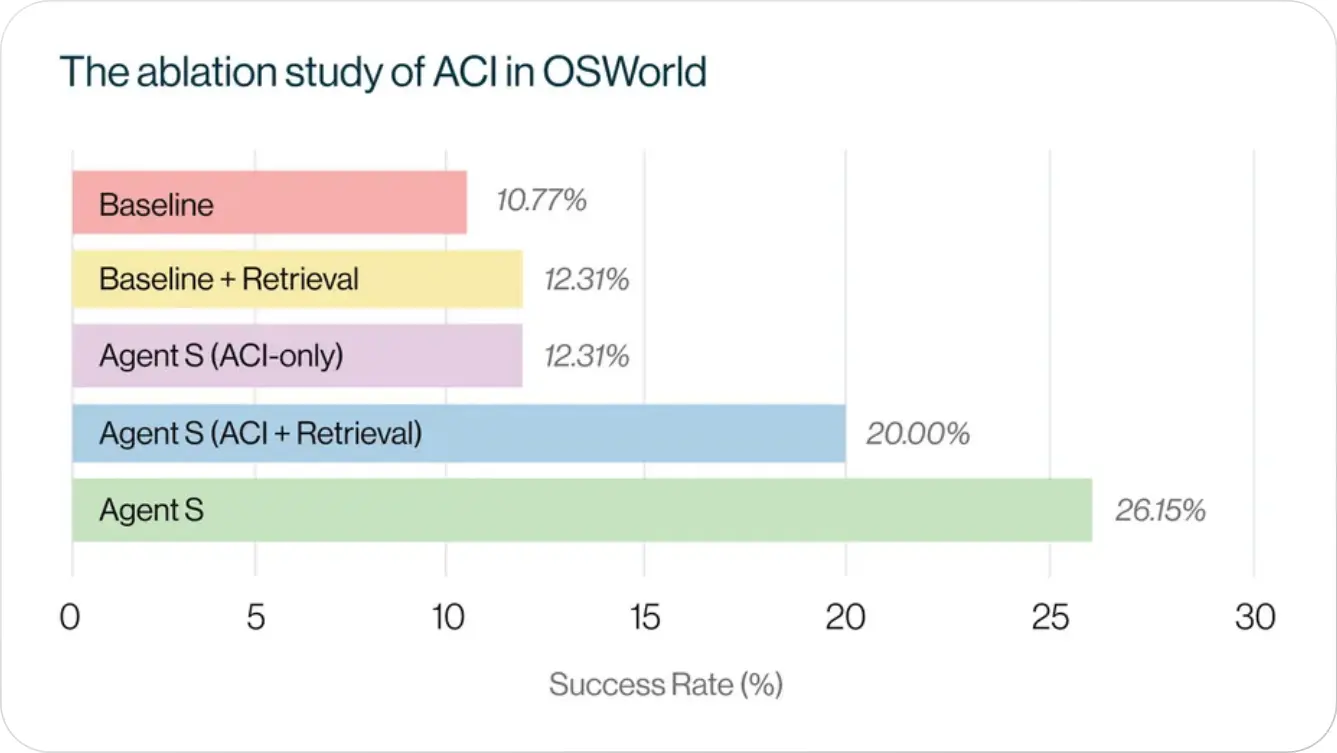

ACI entlockt LLMs bessere Denkfähigkeiten und unterstützt besseres agentisches Lernen
Der Vergleich des Ausgangswerts mit dem Wirkstoff S (nur ACI) verdeutlicht die verbesserten Denkfähigkeiten, die durch die Einbeziehung von ACI erreicht werden. Darüber hinaus untersuchten wir die Auswirkungen von ACI auf das agentische Lernen, indem wir den Prozess des Erfahrungslernens integriert haben. Als Ausgangsbasis verbesserte das Hinzufügen von Erfahrungslernen die Gesamtleistung leicht. In Kombination mit Agent S (nur ACI) verbesserte sich die Leistung jedoch erheblich, was die Wirksamkeit von ACI bei der Verbesserung des agentischen Lernens unter Beweis stellte
Hierarchische Planungsunterstützung
Workflows mit langem Horizont
Das reine ACI-Setup + Experiential Learning in zeigt die Leistung von Agent S ohne hierarchische Planung und den beobachteten Leistungsabfall Agent S (26,15% bis 20,00%) im Vergleich zur Vollversion unterstreicht die Bedeutung der hierarchischen Planung bei der Modellierung langfristiger Arbeitsabläufe. Der Effekt der hierarchischen Formulierung wird bei erfahrungsorientiertem Lernen deutlich, da der Manager in der Planungsphase der Teilaufgaben detailliertere und genauere Pläne erstellen kann.
Exploration, Continual Memory Update und Self-Evaluator sind für die Gedächtniskonstruktion unverzichtbar
Durch das Entfernen der Exploration werden Speicheraktualisierungen nur auf die Inferenzphase beschränkt. Das Entfernen der kontinuierlichen Speicheraktualisierung bedeutet, dass wir nur den Speicher verwenden, der in der Explorationsphase gewonnen wurde, ohne nachfolgende Aktualisierungen. Das Entfernen des Selbstbewerters beinhaltet das Ersetzen zusammengefasster Erfahrungen durch die ursprünglichen vollständigen Trajektorien. Die Ergebnisse zeigen, dass die Verzögerung sowohl der kontinuierlichen Gedächtnisaktualisierung als auch der Phase der selbstüberwachten Erkundung zu einem Leistungsabfall führt, wobei die selbstüberwachte Erkundung viel wirkungsvoller ist. Die Ablation des Self-Evaluators zeigt außerdem, welche Vorteile es hat, zusammengefasste Trajektorien statt vollständiger Trajektorienbeispiele für die Planung zu verwenden.
Verallgemeinerung auf Verschiedenes Betriebssysteme
Wir testen das Agent S-Framework ohne Änderungen auf WindowsAgentArena, einem Windows-Betriebssystem-Benchmark, der gleichzeitig mit unserer Arbeit veröffentlicht wurde. Wir vergleichen Agent S mit der ähnlichen Konfiguration mit GPT-4o als MLLM-Backbone, Accessibility Tree + Image als Eingabe und Parsen mit OCR. Wie in der Tabelle gezeigt, übertrifft Agent S den Navi-Agenten, ohne dass eine Anpassung an die neue Windows-Umgebung erforderlich ist.
Ergebnisse der Erfolgsrate (%) auf WindowsAgentArena unter Verwendung von GPT-4O und Bild+Accessibility Tree-Eingabe im vollen Umfang
BibTeX
Bereit, dein zu benutzen
Computer auf ähnliche Weise?
Teile und organisiere dein Gedächtnis und personalisiere deine Aufgaben.