
Agente S: uma estrutura de agente aberta que usa computadores como um ser humano
Ei! Há alguns meses, dei uma palestra na Universidade de Princeton sobre minhas ideias sobre agentes e Simular. Achei que deveria montar um resumo e transformá-lo em uma postagem no blog.
Desempenho de última geração
Meu primeiro emprego foi como pesquisador no Google DeepMind, onde uma parte fundamental da minha função envolvia colaborar com várias equipes de produtos do Google para identificar oportunidades de aplicar nossa tecnologia de inteligência artificial de ponta. No entanto, um Googler me fez uma pergunta totalmente não relacionada que pode ter desencadeado minha decisão de deixar o DeepMind e iniciar o Simular.
O agente S é um nova agência
estrutura projetado para permitir
computadores a serem usados como
intuitivamente, como um humano faria
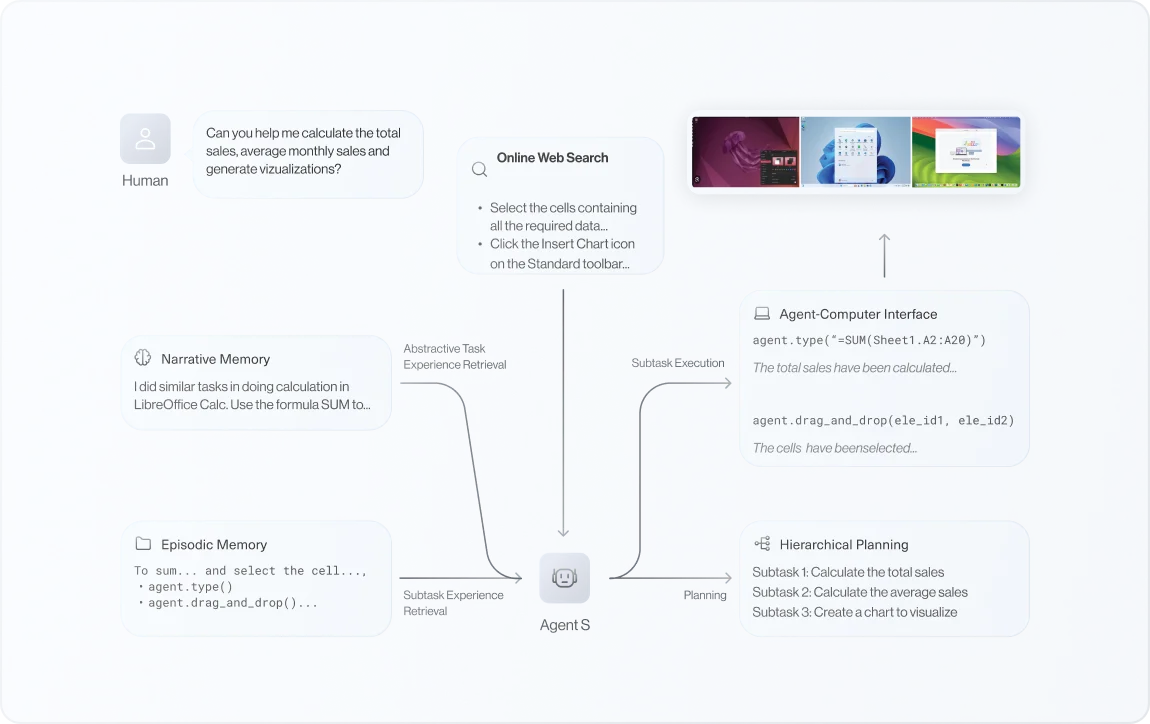
Apresentamos um método de planejamento hierárquico com experiência aumentada. Esse método utiliza o Online Web Knowledge para obter informações atualizadas sobre softwares e sites que mudam com frequência, junto com a Memória Narrativa para aproveitar experiências de alto nível de interações anteriores. Ao dividir tarefas complexas em subtarefas gerenciáveis e usar a Memória Episódica para orientação passo a passo, o Agente S refina continuamente suas ações e aprende com a experiência, alcançando um planejamento de tarefas adaptável e eficaz.
Abstrato
Apresentamos o Agent S, uma estrutura de agente aberta que permite interação autônoma com computadores por meio da interface gráfica de usuário (GUI), com o objetivo de transformar a interação humano-computador automatizando tarefas complexas de várias etapas
Para esse fim, o Agente S introduz o planejamento hierárquico com aumento de experiência, que aprende com a busca externa de conhecimento e a recuperação interna da experiência em vários níveis, facilitando o planejamento eficiente de tarefas e a execução de subtarefas.
Além disso, ele emprega uma interface agente-computador para melhor obter as capacidades de raciocínio e controle dos agentes de GUI com base em modelos multimodais de grande linguagem. A avaliação do benchmark OSWorld mostra que o Agente S supera a linha de base em 9,37% na taxa de sucesso (uma melhoria relativa de 83,6%) e alcança um novo estado da arte. Uma análise abrangente destaca a eficácia de componentes individuais e fornece informações para melhorias futuras.
Além disso, o Agente S demonstra ampla generalização para diferentes sistemas operacionais em um recém-lançado
Referência do Windows Agent Arena.
O Agente S aborda três desafios principais na automatização de tarefas do computador:

Instrução de tarefas
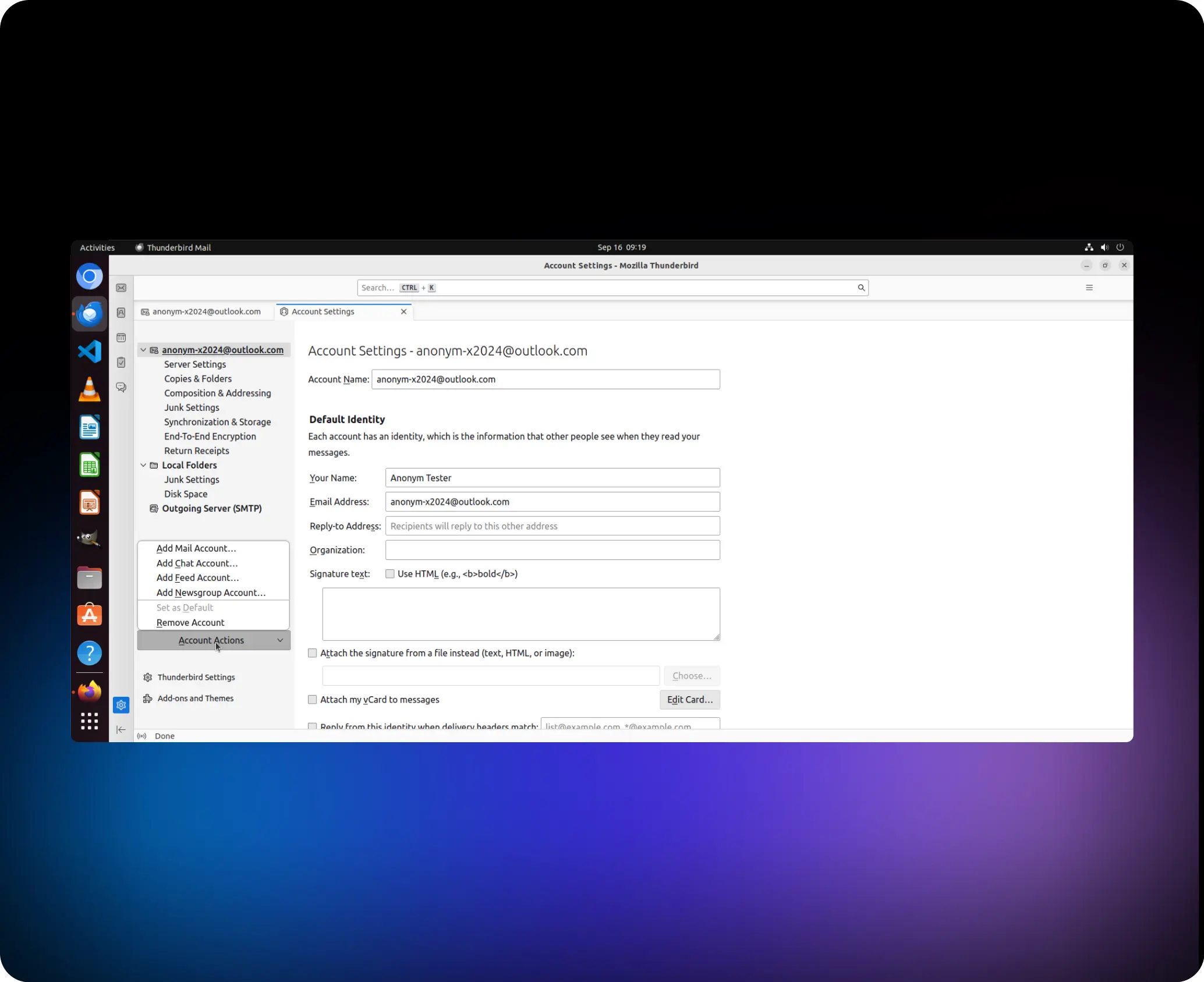
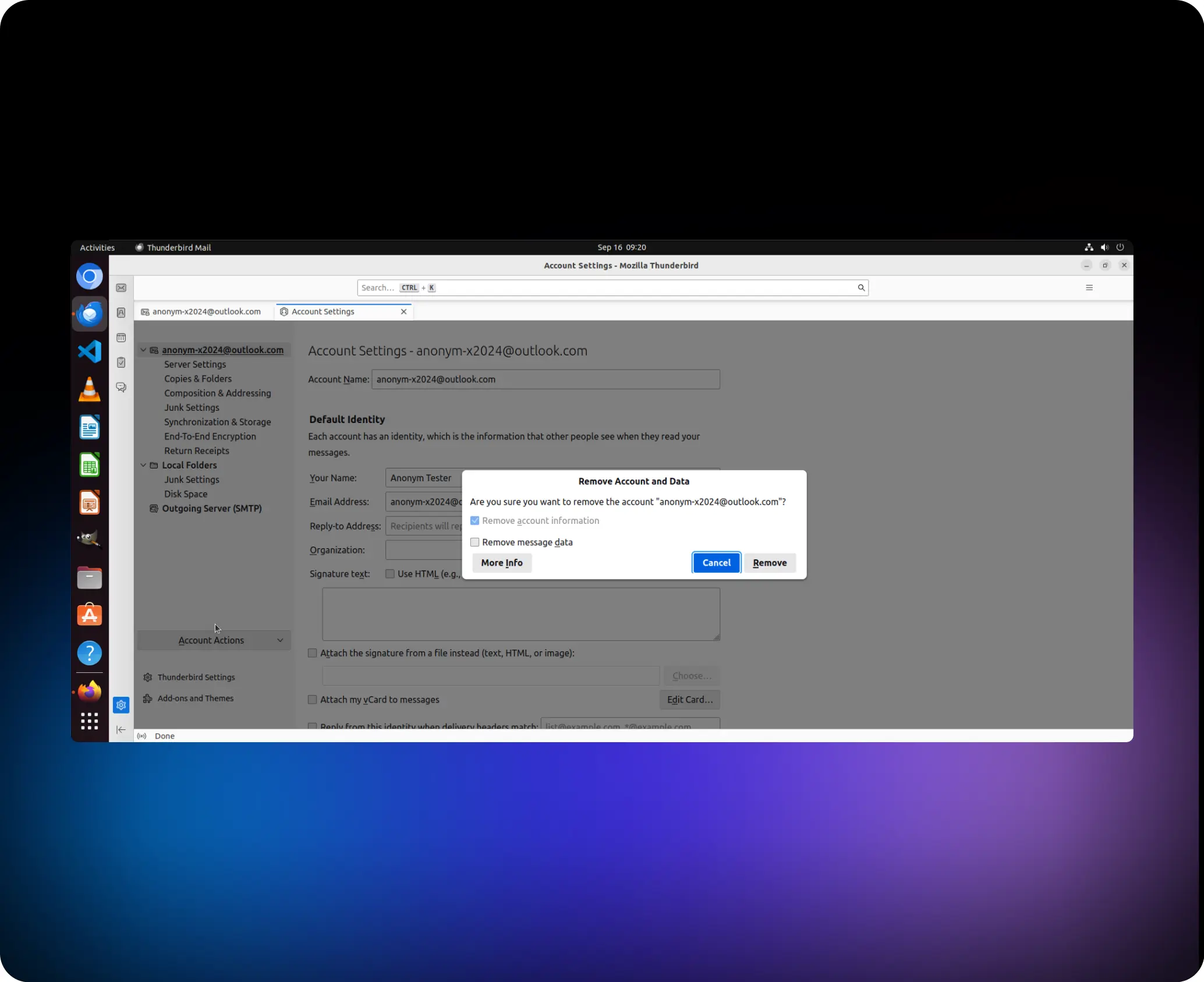
Ajude-me a remover a conta “anonym-x2024@outlook.com”
01
agent.click (41,1, “esquerda”)

02
agent.switch_applications (“Thunderbird”)
03
agent.click (95,1, “esquerda”)
04
agent.click (86, 1, “esquerda”)
05
agent.click (93, 1, “esquerda”)
06
agent.click (149, 1, “esquerda”)
.webp)
.webp)
Visão geral do Agent S Framework
Dada a tarefa Tu e a observação inicial do ambiente 0o, o gerente conduz um planejamento hierárquico com experiência aumentada usando conhecimento da web e memória narrativa para produzir subtarefas So,..., Sn. Para cada Si, o Worker Wi usa a memória episódica para gerar uma ação no momento t, que é executada pelo ACI para retornar a próxima observação imediata de+1. Um módulo de autoavaliação fecha o ciclo armazenando a subtarefa resumida e as trajetórias completas da tarefa na memória narrativa e episódica.
Pipeline de Construção de memória e atualização
O pipeline de construção e atualização da memória, que contém duas fases: exploração autosupervisionada e atualização contínua da memória. A memória narrativa e episódica inicial é construída por meio de algumas tarefas selecionadas aleatoriamente durante a fase de exploração e, em seguida, é atualizada continuamente com base nas tarefas de inferência.
Resultado principal
Esta tabela mostra a comparação de desempenho entre o Agente S e os modelos básicos, avaliados em todo o conjunto de testes do OSWorld. Para o modelo GPT-4o, o Agente S atinge uma taxa de sucesso geral de 20,58%, quase dobrando o desempenho da melhor linha de base correspondente (GPT-4o com 11,21%).
O agente S supera consistentemente as linhas de base nas tarefas “Diárias” e “Profissionais”, onde atinge taxas de sucesso de 27,06% e 36,73%, respectivamente, em comparação com os melhores resultados basais de 12,33% e 14,29%. Essas tarefas são comumente usadas na vida diária ou envolvidas em aplicações profissionais intensivas em conhecimento, que se beneficiam mais do aumento de recuperação do Agente S. Tanto o Claude-3.5-Sonnet quanto o GPT-4o superam as versões básicas na maioria das tarefas. O Claude-3.5-Sonnet ainda tem um desempenho melhor do que o GPT-4o em tarefas “diárias” e “profissionais”.
Os resultados demonstram a capacidade aprimorada do Agente S em lidar com tarefas diversas e complexas de forma mais eficaz do que as abordagens básicas.
Análise
Para demonstrar a eficácia de módulos individuais do Agente S, estratificamos uma amostra de um subconjunto de 65
exemplos, testsubb do conjunto completo de testes para o estudo de ablação. Considerando o custo de inferência, utilizamos o GPT-4o como
Estrutura do LLM para todos os estudos de ablação, tanto para a linha de base quanto para o Agente S.
Aprender com a experiência aprimora o conhecimento de domínio dos agentes de GUI
Principais resultados da taxa de sucesso (%) no conjunto completo de testes do OSWorld de todos os 369 exemplos de testes
Aprender com a experiência universal disponível como conhecimento da web permite que o Agente S faça planos informados em uma ampla variedade de tarefas e tenha o impacto mais significativo. O aprendizado com as memórias narrativas e episódicas tem uma sinergia eficaz com a recuperação na web, e os resultados detalham como sua ablação afeta a capacidade do agente de lidar com tarefas complexas, ressaltando o valor da aprendizagem experiencial. Esses resultados demonstram que cada componente desempenha um papel fundamental no aprimoramento do conhecimento de domínio do agente. A remoção de todos os três componentes (sem todos) degrada significativamente o desempenho, revelando a importância de aprender com a experiência no design.
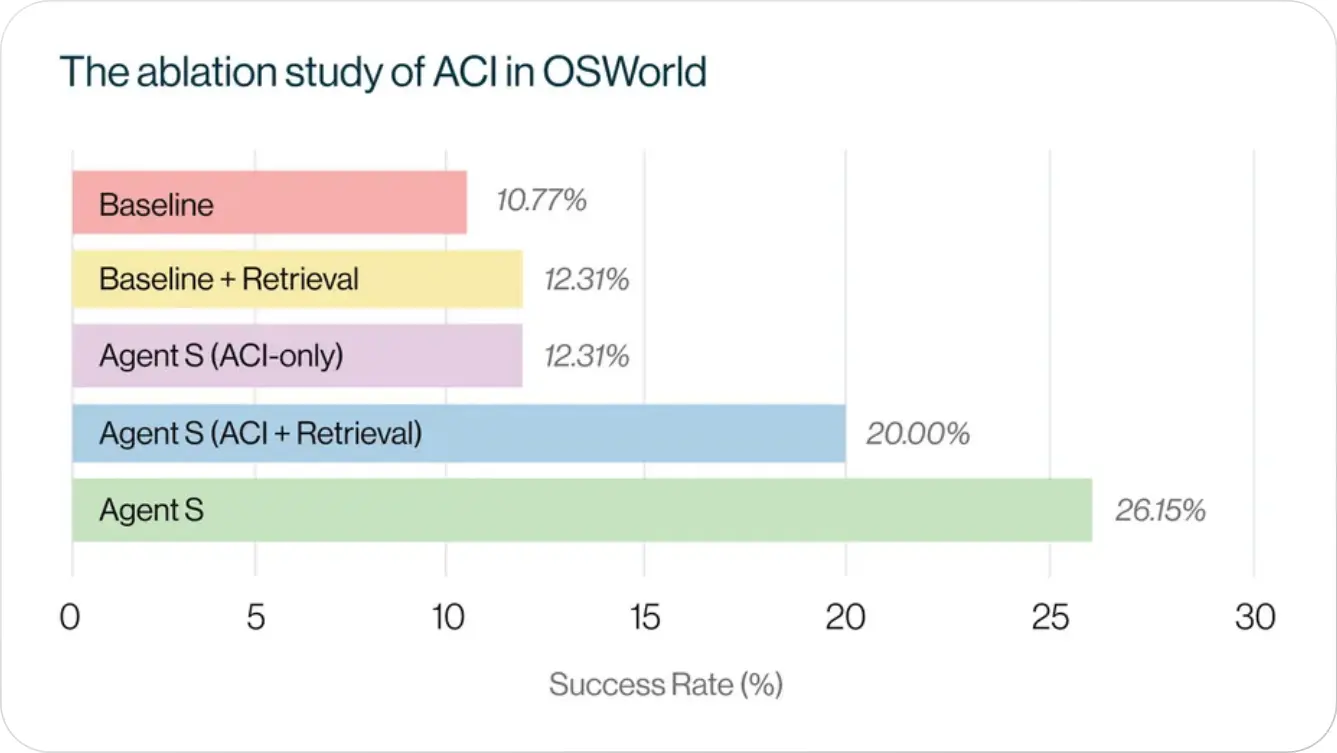

O ACI provoca melhores habilidades de raciocínio dos LLMs e oferece suporte a um melhor aprendizado agente
A comparação da linha de base com o Agente S (somente ACI) destaca as habilidades aprimoradas de raciocínio obtidas com a incorporação da ACI. Além disso, examinamos o impacto da ACI na aprendizagem agente, integrando o processo de aprendizagem experiencial. Para a linha de base, adicionar a aprendizagem experiencial melhorou um pouco o desempenho geral. No entanto, quando adicionado ao Agente S (somente ACI), o desempenho melhorou significativamente, demonstrando a eficácia do ACI em aprimorar o aprendizado agente
Suportes de planejamento hierárquico
fluxos de trabalho de longo horizonte
A configuração ACI Only + Experiential Learning em mostra o desempenho do Agente S sem planejamento hierárquico e a queda de desempenho observada (26,15% a 20,00%), em comparação com o Agente S completo, ressalta a importância do planejamento hierárquico na modelagem de fluxos de trabalho de longo horizonte. O efeito da formulação hierárquica se torna pronunciado na presença do aprendizado experiencial, pois o gerente pode gerar planos mais detalhados e precisos no estágio de planejamento da subtarefa.
Exploração, atualização contínua da memória e autoavaliador são indispensáveis para a construção da memória
A remoção da exploração limita as atualizações de memória somente à fase de inferência. Remover a atualização contínua de memória significa que usamos somente a memória obtida na fase de exploração sem atualizações subsequentes. A remoção do autoavaliador envolve substituir as experiências resumidas pelas trajetórias completas originais. Os resultados revelam que a eliminação das fases de atualização contínua da memória e da exploração autosupervisionada resulta em uma queda de desempenho, com a exploração autosupervisionada sendo muito mais impactante. A ablação do autoavaliador mostra ainda os benefícios de usar trajetórias resumidas em vez de exemplos completos de trajetórias para o planejamento.
Generalização para diferentes Sistemas operacionais
Testamos a estrutura do Agent S sem nenhuma modificação no WindowsAgentArena, um benchmark do sistema operacional Windows lançado simultaneamente com nosso trabalho. Comparamos o Agente S com a configuração semelhante com GPT-4o como backbone MLLM, Accessibility Tree + Image como entrada e análise com OCR. Conforme mostrado na tabela, o Agente S supera o agente Navi sem qualquer adaptação ao novo ambiente Windows.
Resultados da taxa de sucesso (%) no WindowsAgentArena usando a entrada GPT-4o e Image + Accessibility Tree na íntegra
BibTeX
Pronto para usar seu
computador de forma semelhante?
Compartilhe e organize sua memória e personalize suas tarefas.